常见集合篇
ArrayList
数据结构
数组
索引从0开始

数组获取元素的方式是索引+寻址公式,
如果下标从1开始, 那么cpu多一条减法指令要执行, 性能较差.
操作数组
一查找
- 随机查找(即按索引查找) O(1)
- 未排序查找 O(n)
- 排序后二分 O(logn)
二插入和删除 O(n)
由于是连续的空间, 所以挪位置非常耗时间 O(n)
源码分析
添加与扩容机制
ArrayList 底层是基于动态数组实现的。
默认构造方法创建时内部数组长度为 0,是懒初始化。
第一次 add 时才分配默认容量 10。
当元素个数超过当前容量时会触发grow方法扩容。
扩容方式为 oldCapacity + oldCapacity >> 1,即 1.5 倍扩容。
底层通过 Arrays.copyOf 进行数组拷贝。
扩容操作时间复杂度为 O(n),但均摊时间复杂度为 O(1)。
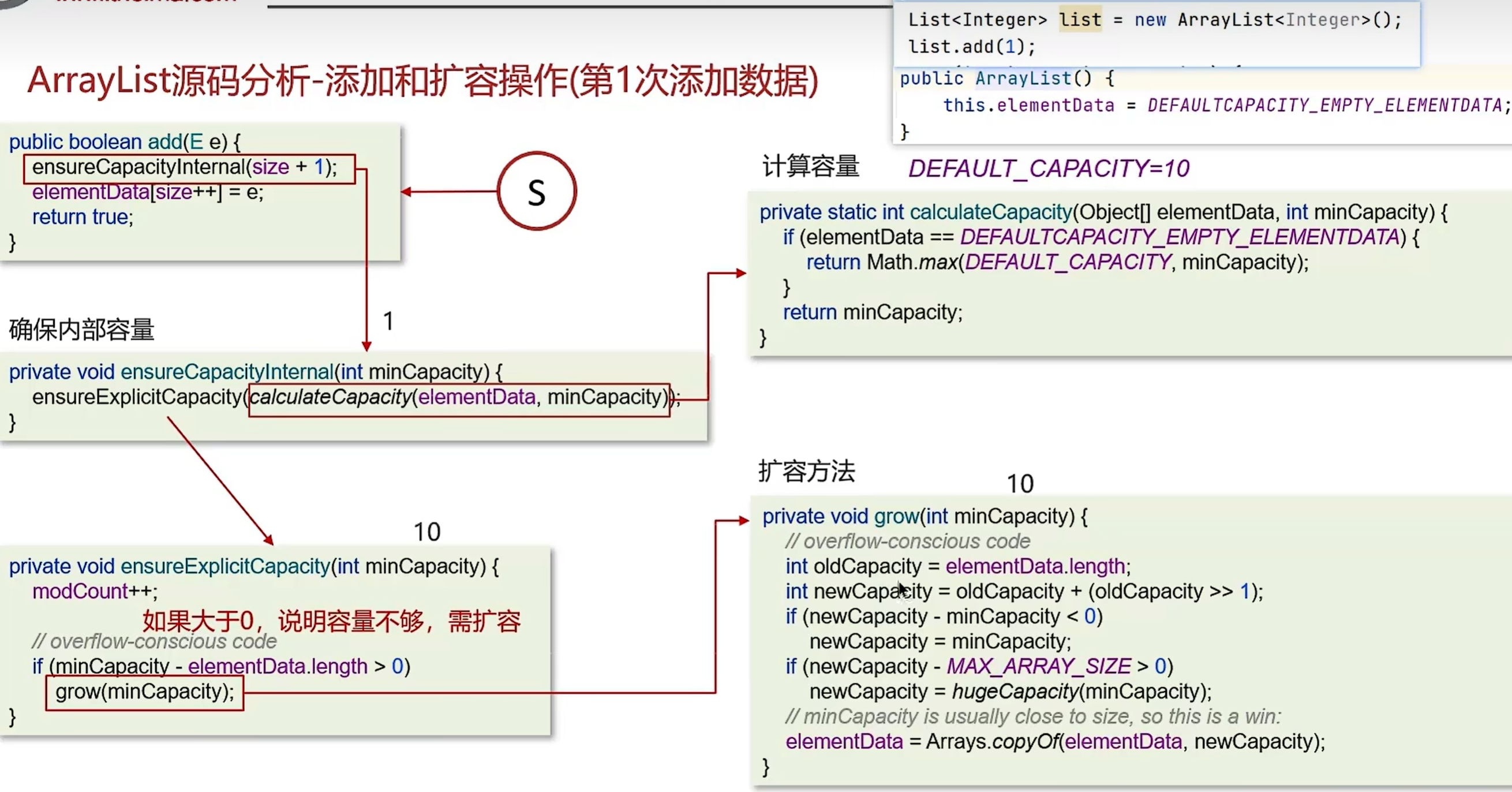
构造方法*3

实现原理

数组和list转换
asList->返回list
对数组进行封装, 然后最后还是引用的传入数组的地址, 所以原数组和list同步变动!
并且新list不可add和remove, 就是和原数组一样是死的
ArrayList和LinkedList的区别:
底层效率空间安全
1.底层结构上: A是动态数组, L是双向链表
2.操作效率:
A查找是O(1), L是O(n),
A增删是O(n), L是O(1),
3.A是连续内存, 节省空间
L是两个指针加数据, 更消耗空间
4.二者都不是线程安全的数据结构
那么如何保证线程安全?
a.在方法内, 尽量使用局部变量
b.用Collections.synchronizedList()封装返回得到线程安全的二者

HashMap
应用: 红黑树
特质
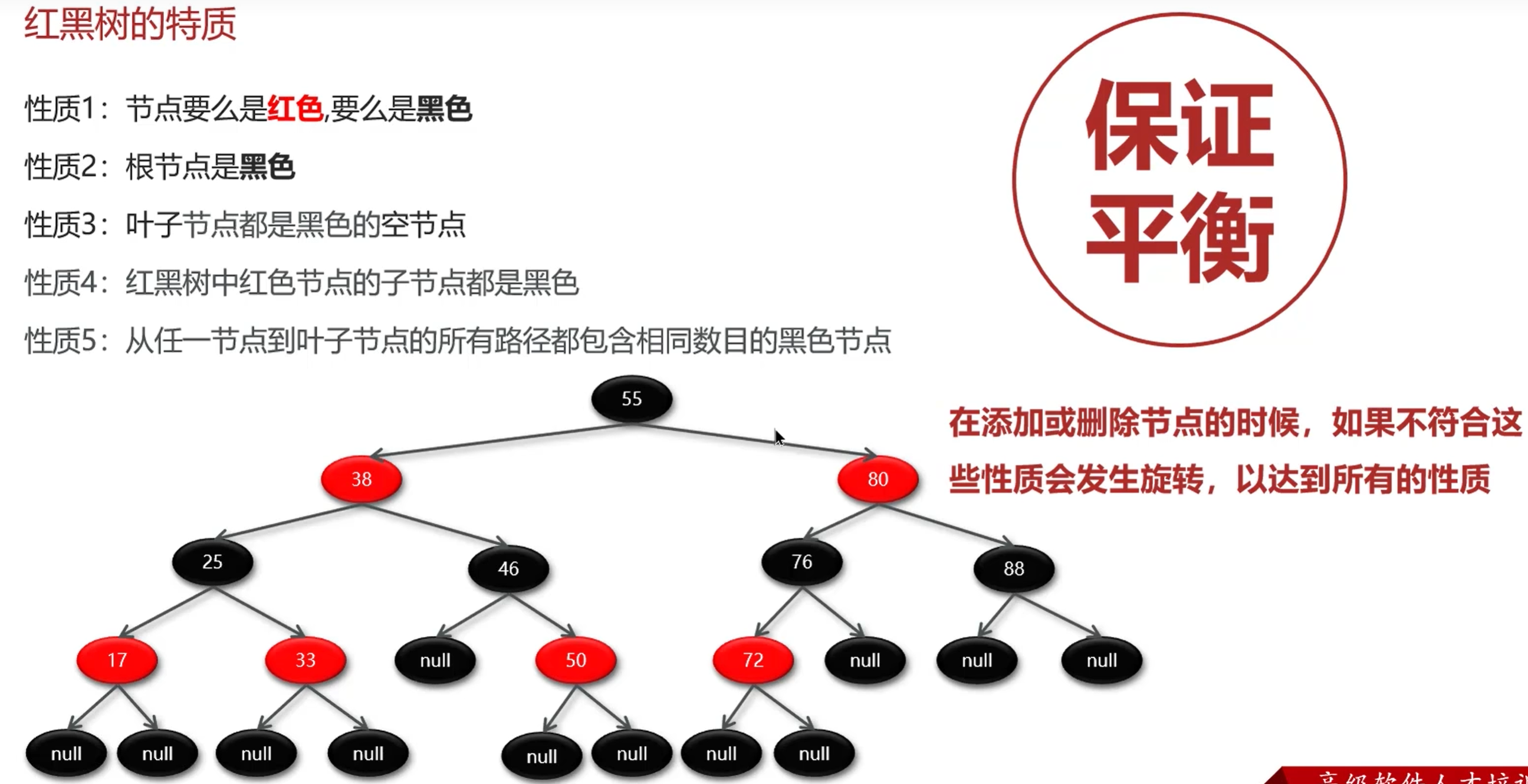
增删改查(logn)
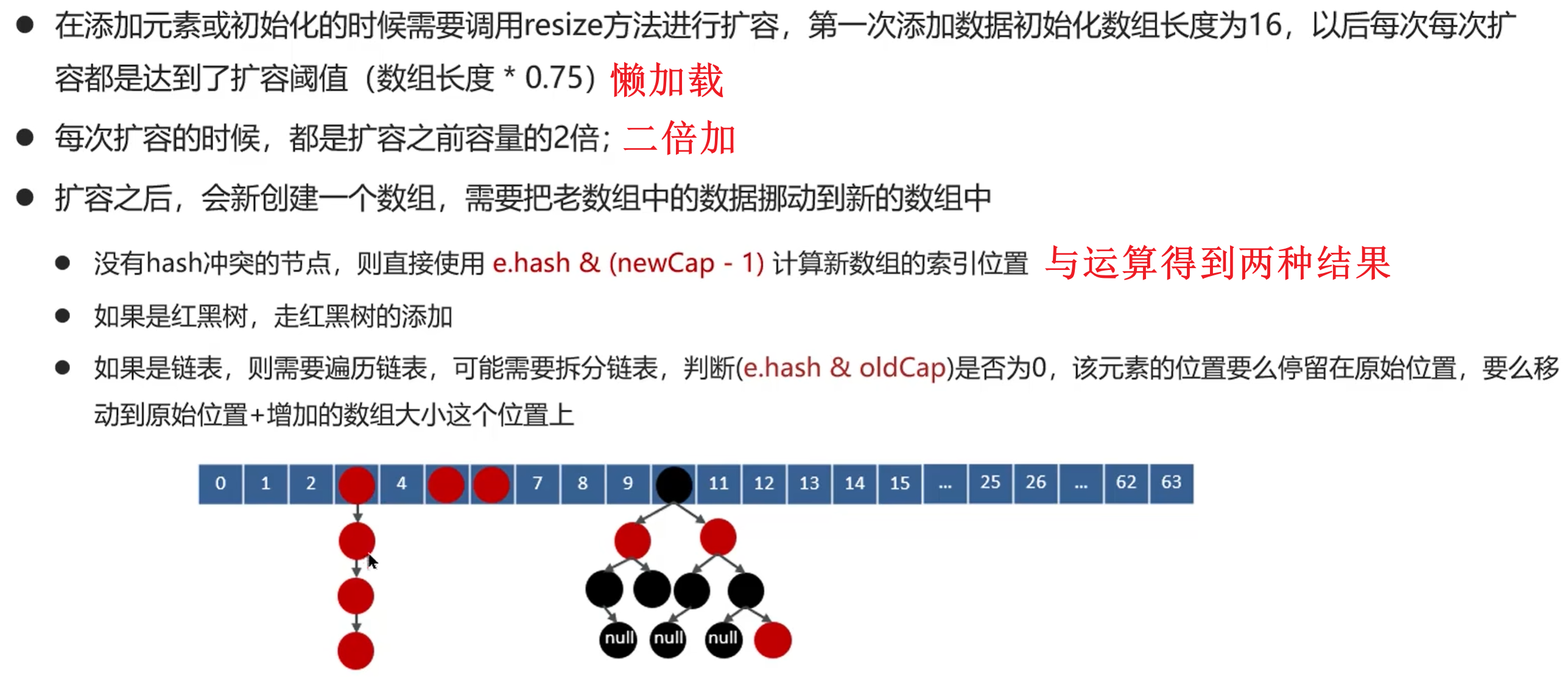
实现原理: 数组 链表 红黑树
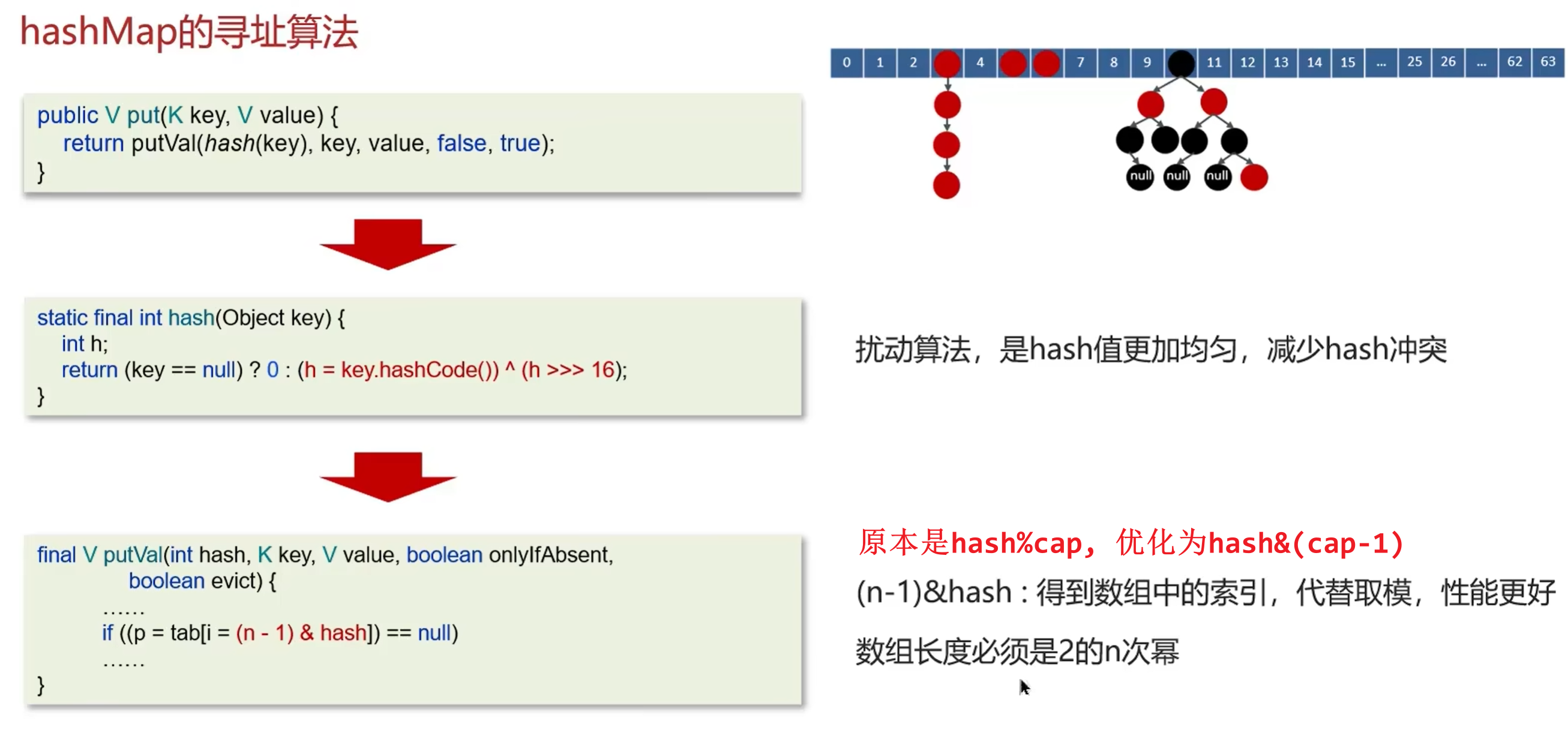
1.hashmap在put元素时, 会hash出key的hashcode然后根据下标找到数组中的位置
2.如果位置已经被占用, 若key相同则覆盖旧value;
不同则将key-value加入链表or红黑树(链表长度>8 && 数组长度>64)中
3.获取时, hash获得下标, 紧接着判断key是否相同, 从而找到对应值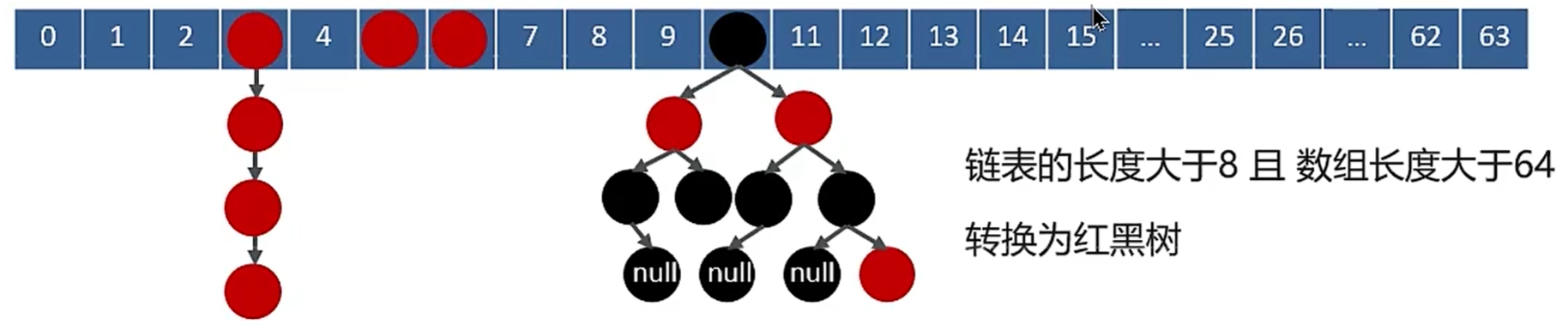
jdk1.7/1.8
1.7及以前用的是拉链法&&头插法, 即链表和数组的组合
1.8之后在链表>8且数组>64时, 会将链表优化为红黑树以减少搜索时间(尾插法)
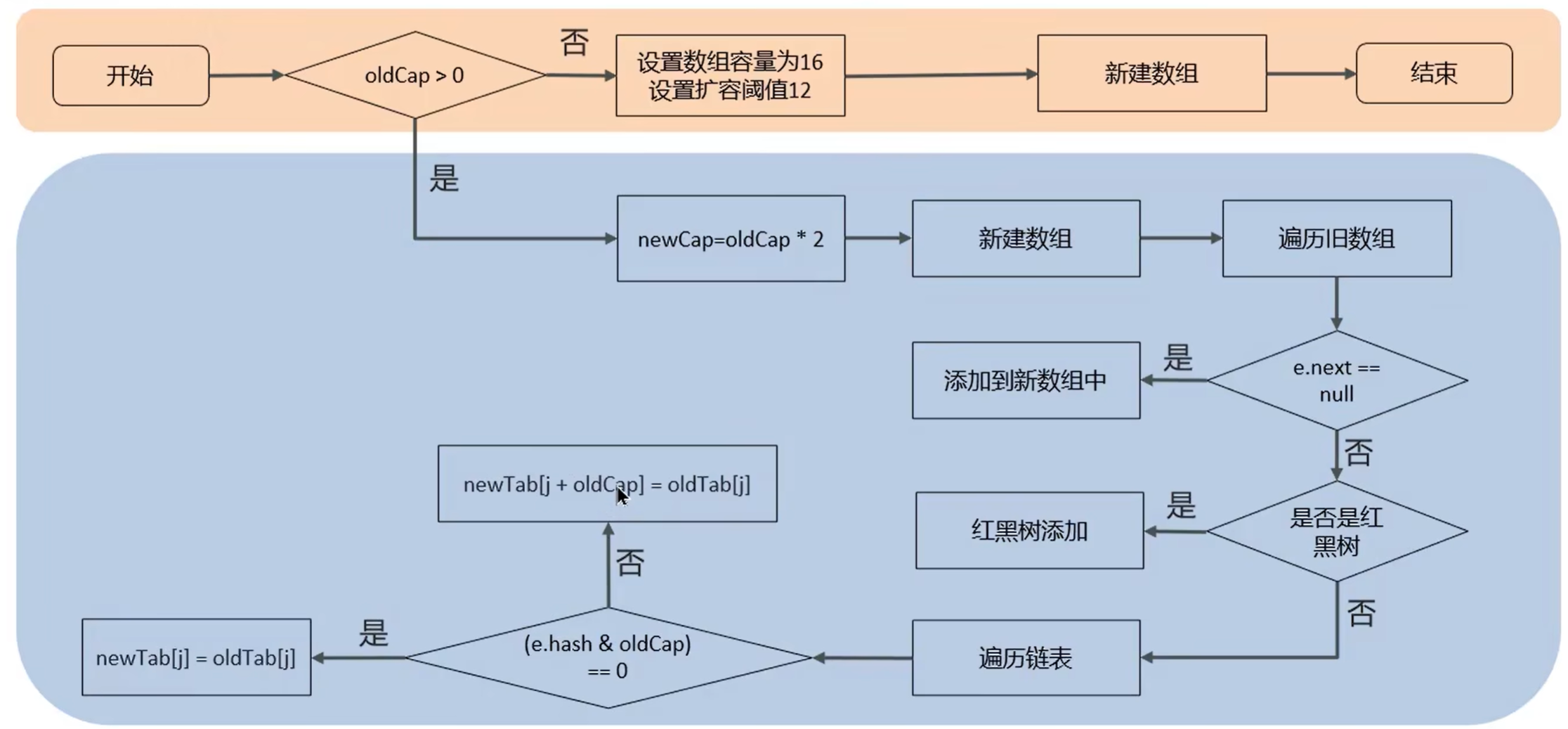
put方法实现原理
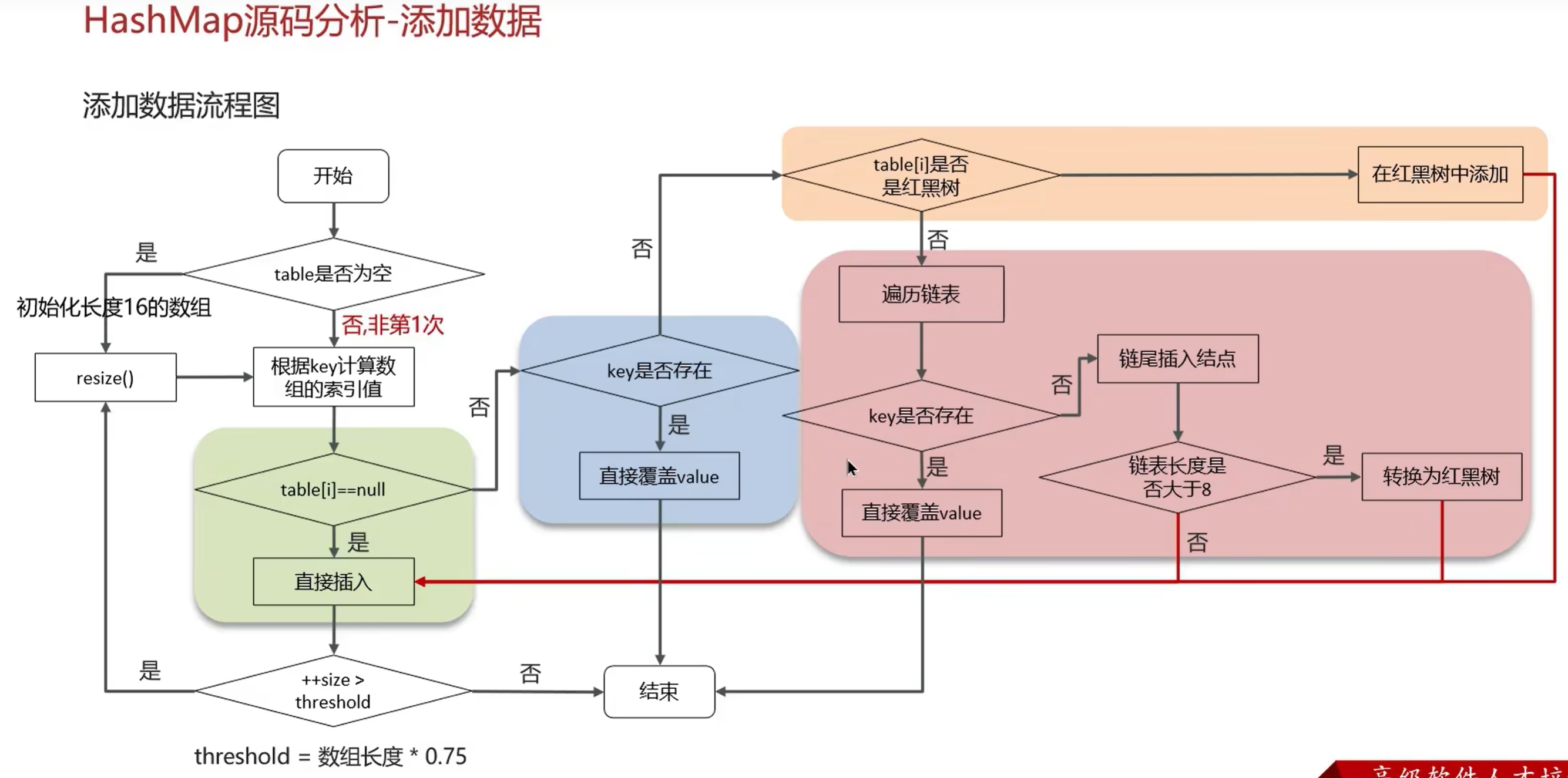

扩容实现: 用 hash & oldCap
不rehash!!!!!!!!!!!!!
==HashMap 容量是 2 的幂,因此扩容为 2 倍时只新增一位二进制。
新的 index 只可能是原 index 或 index + oldCap,因此只需要判断 (hash & oldCap)==
比如
oldcap = 16->10000,
hashcode =1xxxx,
则index = hashcode & 01111 = 0xxxx
扩容
newcap = 32 -> 100000
hashcode = 1xxxx
则index = hashcode & 11111 = 1xxxx -> = oldcap + oldindex
所以其实index = hashcode & (cap-1),
这里的cap-1其实就是一种mask,
当mask新增一位hashcode该位是1, 则new index = oldcap + oldindexhashcode该位是0, 则new index = oldindex
你现在最该记住的是这 4 个点:
- 默认不是一上来就真的 new 16 个桶,而是首次插入时才初始化数组(懒加载)
- 触发条件是
size > threshold - 两倍扩容. 迁移数据时, 扩容不是“重新 hash 一遍”,而是“看新增这一位”.
- 新位置只可能是
j或j + oldCap
寻址算法 = 扰动 + hash&(cap-1)
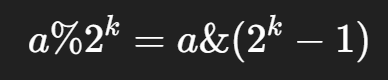 当 `b = 2^k` 时,`a % b` 等价于取 `a` 的最低 `k` 位。
因为 `b-1 = 2^k -1` 的二进制正好是低 `k` 位全 1,
所以 `a & (b-1)` 会保留 `a` 的最低 `k` 位,清掉更高位。
而高位部分都是 `2^k` 的倍数,不影响余数,所以两者相等。
当 `b = 2^k` 时,`a % b` 等价于取 `a` 的最低 `k` 位。
因为 `b-1 = 2^k -1` 的二进制正好是低 `k` 位全 1,
所以 `a & (b-1)` 会保留 `a` 的最低 `k` 位,清掉更高位。
而高位部分都是 `2^k` 的倍数,不影响余数,所以两者相等。

JDK 7 多线程死循环问题
1 | Entry<K,V> next = e.next; 1 |
初链表: a->b->null
T1: e=a, next = b
T2抢占后: b->a->null
接着T1回来了(其数据任然是e=a, next=b, 下一步执行2)
计算a.next=newTable[i]!
此时的newTable[i]即为b
导致a->b->a循环了!
6666